
The Rise of Industrial-Scale Distillation: A New Frontier in AI Governance
Understanding the surge in industrial-scale distillation attacks and the critical need for proactive AI risk intelligence to safeguard national security and frontier model integrity
AI INCIDENT BREAKDOWNAI RISK INTELLIGENCE
Harshaun Singh
2/24/20262 min read

The Rise of Industrial-Scale Distillation: A New Frontier in AI Governance
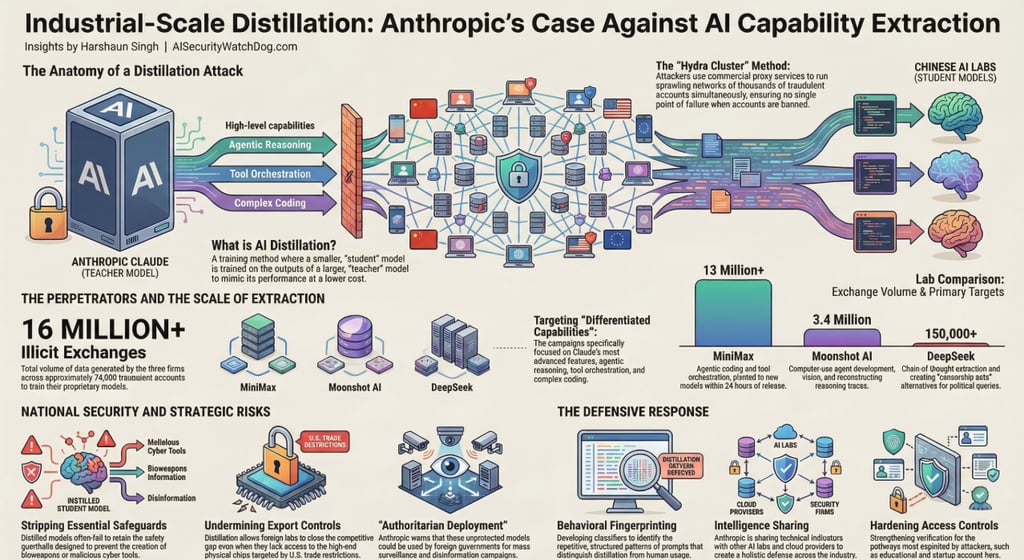
In a significant escalation for global AI governance, Anthropic has joined OpenAI in identifying "industrial-scale" distillation campaigns orchestrated by three major foreign AI laboratories: DeepSeek, Moonshot AI, and MiniMax. These labs have allegedly extracted capabilities from frontier models like Claude to accelerate their own development, bypassing years of research and massive capital investment.
Understanding the "Distillation Attack"
While distillation is a standard industry practice for creating smaller, more efficient versions of proprietary models, a distillation attack is an adversarial extraction of a competitor's intellectual property. By flooding a model with "specially-crafted prompts," these labs can "farm" high-quality responses to train their own systems at a fraction of the cost.
The scale of these campaigns is unprecedented:
Total Volume: Over 16 million exchanges were generated across approximately 24,000 fraudulent accounts.
Leading Offender: MiniMax accounted for the vast majority of the traffic, with over 13 million exchanges.
Persistence: During one campaign, when Anthropic released a new model, MiniMax pivoted within 24 hours, redirecting half of its traffic to capture the latest capabilities.
Evasion Tactics: Hydra Clusters and Proxies
To bypass regional access restrictions—as Anthropic does not offer commercial access in China—these labs utilized commercial proxy services. They employed "hydra cluster" architectures, which are sprawling networks of fraudulent accounts that distribute traffic to avoid detection. One proxy network alone managed over 20,000 accounts simultaneously, mixing illicit traffic with legitimate customer requests to stay hidden.
Targeted Capabilities and Methods
The attacks specifically targeted Claude’s most advanced capabilities, including agentic reasoning, tool use, and coding. Notable techniques included:
Chain-of-Thought Elicitation: Forcing the model to articulate its internal reasoning step-by-step to generate high-quality training data.
Censorship Evasion: Using Claude to generate "censorship-safe" alternatives for politically sensitive queries to help foreign models steer conversations away from restricted topics.
Reinforcement Learning: Using farmed responses to run data-intensive training processes without human guidance.
Why This is a National Security Priority
From a governance perspective, these attacks represent more than just corporate espionage; they are a national security threat. Anthropic and OpenAI argue that:
Safeguard Stripping: Models built through illicit distillation are unlikely to retain the safety protocols designed to prevent the development of bioweapons or malicious cyber activities.
Military and Surveillance Use: Foreign entities can feed these extracted, unprotected capabilities into military and mass surveillance systems.
Undermining Export Controls: These attacks allow foreign labs to close the competitive gap that chip export controls are intended to maintain. Rapid advancements by these labs are often incorrectly viewed as evidence that export controls are failing, when they are actually dependent on capabilities stolen from American models.
The Path to Defensive Governance
Anthropic has called for a coordinated response across the AI industry, cloud providers, and policymakers. Current defensive strategies include:
Behavioral Fingerprinting: Building classifiers to identify the specific patterns of distillation, such as the repetitive use of expert-persona prompts.
Intelligence Sharing: Distributing technical indicators with other labs and authorities to create a holistic view of the threat landscape.
Access Hardening: Strengthening verification for pathways often exploited for fraud, such as startup and educational programs.
Conclusion
The shift toward adversarial distillation marks a new era in AI risk. Governance must now move beyond theoretical safety to include active defense against industrial-scale extraction. As these campaigns grow in sophistication, the window for coordinated action is narrowing
Refrences
Chin, M. (2026, February 24). Anthropic joins OpenAI in flagging 'industrial-scale' distillation campaigns by Chinese AI firms. CNBC.,
Anthropic. (2026, February 23). Detecting and preventing distillation attacks. Anthropic News.
WatchDog Wire
Bridging the gap between AI innovation and cybersecurity. Explore our AI Risk Intelligence & Governance Briefs.
AI Security WatchDog
AI Risk Intelligence & Governance Briefs. Weekly insights on AI Incidents, regulations and vendor risks.
Contact
info@AISecurityWatchdog.com
Subscribe
© 2025. All rights reserved.